


Wyobraź sobie, że jesteś programistą i pracujesz w utrzymaniu istniejącego projektu. Załóżmy, że ten kod jest przechowywany na dyskach wspólnych w Twojej firmie. Zanim przystąpisz na naprawy zgłoszonego błędu, musisz odnaleźć projekt na dysku, skopiować jego zawartość do nowego folderu, opatrzyć folder prawidłową datą, zainstalować wszystkie pakiety, zbudować projekt, etc. Możesz zabrać się do naprawy. Teraz wyobraź sobie, że zadanie jest dość złożone i po testach dochodzą kolejne zmiany, a w tak zwanym międzyczasie zmieniła się koncepcja i Twoja wersja zmian sprzed testów powinna zostać przywrócona. Ale przecież nie robiłeś dodatkowego folderu, tylko nadpisałeś wcześniejsze modyfikacje. Brzmi koszmarnie?
Kiedy uczyłam się JavaScriptu, wszędzie wokół słyszałam: „Musisz mieć konto na GitHubie albo BitBuckecie i tam trzymać swój programistyczny dorobek, żeby móc go później pokazać światu. A poza tym musisz rozumieć i korzystać z kontroli wersji„. Przechowywanie kodu w internetach to ja rozumiem, ale kontrola wersji? A na co to komu?
Dziubałam sobie powolutku swoje szufladowe projekciki, zgodnie z wolą programistycznej braci wrzucałam pliki na GitHuba (dosłownie – na początku używałam przycisku Upload File w GH) i zupełnie nie rozumiałam o co tyle szumu z tą kontrolą wersji. Z czasem odkryłam, że przy projektach, które tworzę dłużej niż jedno popołudnie i dodatkowo piszę na różnych sprzętach, fajnie mieć dostęp do tego kodu na bieżąco bez konieczności wrzucania plików na Dropboxa. Obejrzałam pierwszy lepszy kurs Gita i zaczęłam korzystać z jego najbardziej bazowych komend.
Zderzenie z rzeczywistością
Jednak cały czas z tyłu głowy byłam przekonana, że to wiele hałasu o nic i w sumie to spokojnie poradziłabym sobie bez tego całego Gita. I pewnie nic by się nie zmieniło gdybym pracowała jako front-endowiec klepiący wyłącznie statyczne landig pejdże w firmie, w której nie obowiązują żadne standardy. Stało się jednak inaczej.
Sytuacja opisana w leadzie tego wpisu (że dyski wspólne, że poprawki, że nie ma zapisanego kodu) to realny przykład tego, co działo się w mojej pierwszej programistycznej pracy. Pomimo tego, że bugi poprawiałam sama, że nikt w tym samym czasie nie pracował na tym kodzie, że code review prawie nie istniało to i tak dramatem dla mnie było to, że nie mogę bez powtórzenia tej całej procedury z tworzeniem folderów wrócić do wcześniejszej wersji kodu. Jak wspominałam we wcześniejszych wpisach, już tam nie pracuję 😉
Duży projekt bez kontroli wersji?
Rozwojem aplikacji, przy której obecnie pracuję, zajmuje się łącznie kilkunastu programistów, w tym prawie połowa to front-end developerzy. Pochodzimy z kilku różnych miast w Polsce, nierzadko ktoś pracuje zdalnie. Dokładne i rzetelne code review jest raczej standardem niż odstępstwem od normy. QA testują aplikację na specjalnie do tego przygotowanych środowiskach, co pewien czas następują wydania produkcyjne. Jakby to wszystko wyglądało, gdybyśmy korzystali z dysków wspólnych? Oczywiście że jest to możliwe do wykonania, jednak z pewnością nie byłoby to tak proste jak obecnie.
Git flow
Pierwszym co zrozumiałam przy pracy z Gitem w większym projekcie było to, że kod ma wiele różnych wersji. Przykładowo: kiedy dołączyłam do mojego zespołu cały projekt był na etapie przygotowań do wydawania wersji numer 6, co oznaczało ni mniej ni więcej, że coś w wersji 5 już funkcjonuje i najprawdopodobniej jacyś ludzie w ogólnodostępnym internecie mogą z tego korzystać. Ta wersja numer 5, która była wydana i dostępna wcześniej została przetestowana i spełniała jakieś kryteria. Oczywistym jest więc, że bazą do prac nad wersją 6 będzie kod z wersji 5, a nie np. 2 (chyba, że ktoś kto płaci za projekt tak by sobie zażyczył…).
Jeżeli zatem rozpoczynam pracę nad nową funkcjonalnością na wydanie numer 6 to zaczynam od skopiowania w zdalnym repozytorium (czyli w miejscu na serwerze gdzie przechowujemy różne wersje kodu) sobie kodu z wydania numer 5 (tworzę branch – gałąź) i pobieram ją sobie lokalnie na swój komputer [git pull]. Na tej lokalnej kopii wprowadzam zmiany. W każdej chwili mogę moją lokalną wersję kodu wysłać do zdalnego repozytorium i udostępnić innym programistom.
Commity, czyli save pointy w kodzie
Podczas pracy nad kodem mogę zapisywać stan: to coś jak robienie save w grze, tworzenie punktu, do którego można wrócić, albo raczej paczki ze zmianami, którą można potem wysłać na serwer lub nie. Dzieje się to poprzez stworzenie tzw. commita [git commit]. Commitowanie to zatwierdzenie zmian, może zostać opatrzony wiadomością z opisem zmian, które zawiera [git commit -m „wiadomość„] oraz posiada unikalny numer. Wcześniej jednak mogę skorzystać z poczekalni dla plików [git add].
Kiedy skończę swoją pracę mogę wszystkie lub wybrane przeze mnie zmiany (commity) wysłać na serwer [git push]. Teraz moi koledzy z zespołu mogą zapoznać się z moim kodem. Najczęściej odbywa się to poprzez stworzenie pull request, czyli wniosku o scalenie moich zmian z aktualną wersją kodu. Oczywiście nie wnioskuję o dołączenie moich zmian bezpośrednio do kodu z wersji 5: ktoś w międzyczasie utworzył na podstawie kodu z wydania numer 5 gałąź przeznaczoną na rozwój w ramach przyszłej wersji 6. Taka gałąź nazywa się często develop, zaś ta najbardziej „wyjściowa”, produkcyjna wersja kodu często znajduje się na głównej gałęzi zwanej master.
Czytanie kodu – czas na code review
Tworząc swojego pull requesta mogę dodać reviewerów, czyli osoby które proszę, żeby spojrzały na mój kod (czyli zrobiły code review) zanim go scalę z gałęzią develop. Oczywiście w projekcie można ustalić, żeby np. nie było możliwości scalania zmian, zanim ktoś z reviewerów nie zaaprobuje proponowanych zmian.
Reviewerzy mogą oznaczyć kod jako gotowy do scalenia albo wymagający poprawek. Mogą również pisać komentarze do kodu, gdzie zadają pytania albo sugerują pewne zmiany. Przy okazji poznają na bieżąco ze zmianami w kodzie, nad którym również pracują.
Scalanie zmian
Po zaaprobowaniu zmian przez zespół przyszła chwila na scalanie zmian, czyli merge [git merge develop]. To tak naprawdę stworzenie merge-commita i dołączenie commitów z gałęzi, na której pracowałam (inaczaj feature branch) do gałęzi docelowej.
Bardzo możliwym jest, że w czasie kiedy ja pracowałam nad swoimi zmianami ktoś inny dodał do brancha docelowego swoje zmiany. Co się jednak stanie kiedy ta osoba zmodyfikowała tę samą linię kodu, którą ja również zmieniam w jednym ze swoich commitów? Wtedy, proszę Państwa, mamy konflikt (a właściwie conflict) i – jak to w życiu bywa – należałoby ten konflikt rozwiązać.
Konflikty w kodzie
W praktyce to jest tak: wystawiam swojego pull requesta do brancha docelowego. W tym czasie reviewerzy wrzucają swoje komentarze do mojego kodu, ja go poprawiam. W międzyczasie inni programiści też wypychają swój kod do zdalnego repozytorium i tworzą pull requesty do tego brancha docelowego. Kiedy inny programista zmerguje swoje zmiany do brancha docelowego i Git zorientuje się, że ten ktoś zmodyfikował te same linie, które ja również chcę zmodyfikować, dostanę komunikat o konieczności rozwiązania konfliktów.

A może rebase?
Wcześniej napisałam że do scalania zmian służy merge. Jednak innym sposobem na dołączenie swojego kodu do innego brancha jest rebase [git rebase develop], czyli zmiana postawy kodu dla moich zmian. Rebase modyfikuje historię zmian w developie, podczas gdy merge tworzy dodatkowego merge-commita i dołącza commity z feature brancha do developa. Jednak ta modyfikacja historii nie jest zawsze tym, o co nam chodzi i może mieć niechciane konsekwencje, zwłaszcza wtedy, kiedy chcielibyśmy się cofnąć do poprzednich wersji kodu.
Rozwiązywanie konfliktów
W moim przypadku rozwiązywanie konfliktów odbywa się w moim edytorze do pisania kodu. Koncepcja jest bardzo prosta: po lewej stronie mam swoje zmiany (mój feature branch), po prawej mój branch docelowy (np. develop), a w środku edytor do połączenia obu tych wersji.
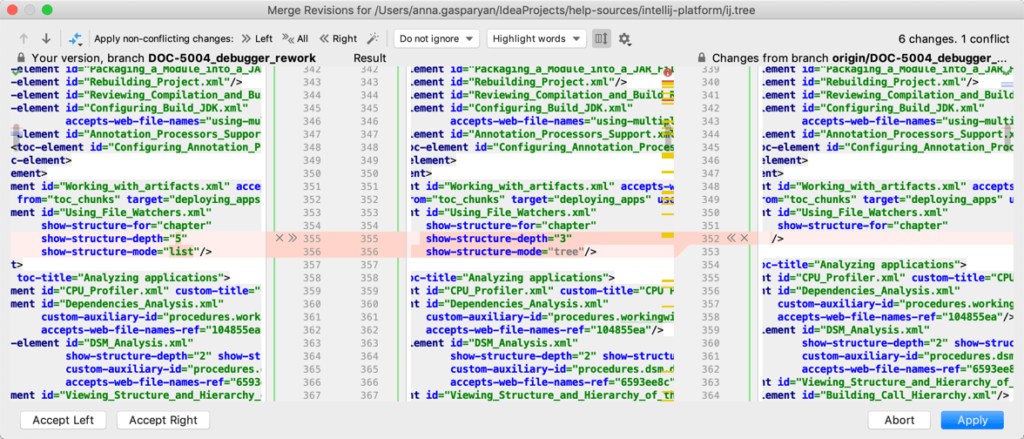
Rozwiązywanie konfliktów bywa mocno męczące. Im więcej zmian doszło do kodu docelowego w czasie kiedy nie uaktualniałam swojego feature brancha, tym więcej dociekania będę mieć przy mergowaniu swoich zmian. Na szczęście w IntelliJ dostępna jest funkcjonalność Annotate, dzięki której można sprawdzić kto i kiedy wprowadził zmiany w developie i zadać autorowi kilka pytań 😉
Schowek
Jedną z super przydatnych funkcji w Git jest schowek [git stash]. Dzięki schowkowi można zapisać niezacommitowane zmiany i wrócić do stanu sprzed wprowadzania zmian i np. przenieść je na inny branch [git stash apply] (może to spowodować powstanie konfliktów, tak samo jak przy mergowaniu zmian).
Co dalej z Gitem?
Tutaj lista funkcjonalności, które oferuje Git wcale się nie kończy. W żadnym wypadku nie jestem Gitowym magikiem, dopiero go poznaję i – jak to mówią – im dalej w las tym więcej drzew. Doceniam jednak potęgę tego narzędzia i staram się zgłębiać swoją wiedzę o nim.